
Every AI chatbot deployed on a business website is answering questions. The critical question is: from where? If the answer is "from the model's general training data," you have a serious problem. General training data knows nothing about your pricing, your policies, your products, or the specific nuances of how your business operates. The model will still generate a confident, well-structured response. It will simply be wrong in ways that are difficult to predict and dangerous to leave unaddressed.
Retrieval-Augmented Generation, almost universally abbreviated as RAG, is the technical architecture that solves this problem. It is the reason modern AI chatbots can give accurate, specific, trustworthy answers about individual businesses rather than plausible-sounding guesses. Understanding RAG at a conceptual level is not a developer concern. It is a business owner concern, because it directly determines whether your chatbot is an asset or a liability.
The Problem RAG Solves
To appreciate RAG, you need to understand the fundamental limitation of large language models (LLMs) operating without it.
LLMs like GPT-4, Claude, or Gemini are trained on enormous datasets of text from the internet, books, and other sources, with a knowledge cutoff at a specific date. They are extraordinarily good at understanding language, reasoning through problems, and generating coherent, natural-sounding text. What they cannot do is know anything that happened after their training cutoff, or anything that was never in their training data.
Your business almost certainly falls into the second category. Unless Paperchat, your software company, or your e-commerce store is prominently featured in publicly available internet text, the model has no knowledge of it. It does not know your return policy. It does not know that you discontinued the starter plan in Q3. It does not know that your shipping partner changed last month.
This creates a specific and well-documented failure mode: confident hallucination on domain-specific questions.
What hallucination looks like in practice. A customer asks your chatbot about your enterprise pricing tier. The model, having no knowledge of your actual pricing, generates a response based on patterns it observed across thousands of SaaS company pricing pages it encountered during training. It describes a tier with features and a price point that sounds plausible. The customer reads this, builds a budget around it, and contacts your sales team expecting a conversation about a pricing structure that does not exist.
The damage from this interaction is not just a single confused prospect. It is a prospect who now has a data point suggesting your company is not reliable, and a sales team that has to undo the confusion before the actual conversation can begin.
Research from Stanford's Human-Centered AI Institute found that hallucination rates for domain-specific questions against ungrounded LLMs range from 35-60%, depending on the specificity of the question and the domain (Stanford HAI, 2025). A chatbot with a one-in-three chance of giving a wrong answer on business-specific questions is not a support tool. It is a trust erosion mechanism.
RAG is the architecture that reduces hallucination rates to 5-15% on domain-specific questions, by grounding the model's responses in content you have explicitly provided (Lewis et al., 2025).
RAG in Plain English
The name is descriptive if you unpack each component:
Retrieval means that before generating any response, the system searches for relevant information from a curated knowledge base. It does not rely on what the model already "knows." It actively looks up relevant content, in real time, in response to the specific question being asked.
Augmented means that the retrieved content is added to the model's context before it generates a response. The model does not just receive the user's question. It receives the question plus the most relevant excerpts from your knowledge base. Its answer is supplemented by, and grounded in, specific content you provided.
Generation means the model still generates a natural language response. It synthesizes the retrieved content, explains it in accessible terms, and delivers it in an appropriate conversational tone. It is not simply returning a stored answer. It is using the retrieved content as the factual foundation for a generated response.
The best analogy for a non-technical audience is a well-prepared consultant. Imagine asking a consultant a detailed question about your company's operational metrics. A consultant who relies purely on memory might give you a broadly plausible but imprecise answer. A consultant who pulls up the relevant report before responding, reads the specific figures, and then explains them will give you a precise, accurate answer. RAG makes AI chatbots work like the second consultant: look it up first, then respond.
The RAG Pipeline: Step by Step
Understanding the sequence makes the whole system more intuitive.
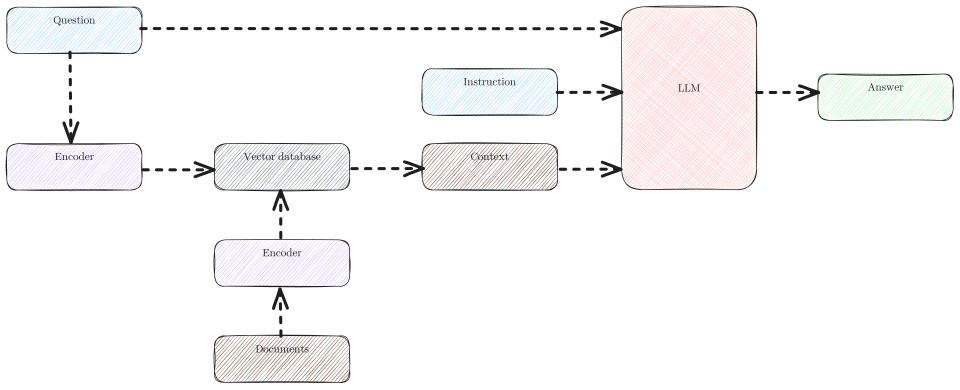
Step 1: User asks a question
A visitor to your website types a question into the chat widget. "What happens if I miss a payment?" or "Does your Pro plan include API access?" or "How long does installation take?"
Step 2: The question is converted to a vector embedding
The system passes the question through an embedding model, which converts it into a numerical vector that represents its meaning. This is not a keyword list. It is a mathematical representation of the question's semantic content: what the question is asking about, at a conceptual level.
This embedding captures meaning rather than words. "How do I cancel?" and "What is the process for ending my account?" produce similar embeddings even though they share no key words, because they express the same intent.
Step 3: Vector similarity search against the knowledge base
The question embedding is compared against the stored embeddings of every chunk in your knowledge base. The database returns the chunks whose embeddings are most similar to the question embedding: the content that is most relevant to what the user is asking.
This is semantic search, not keyword search. It finds relevant content based on meaning, not word matching. A question about "getting a refund" will surface your returns policy even if that policy document uses the words "send back" or "exchange" rather than "refund."
Step 4: Top-K relevant chunks are retrieved
The system selects the top few most relevant chunks, typically between 3 and 10, depending on configuration. These chunks are the passages from your knowledge base that most closely address the user's question.
If someone asks about your API limits, the retrieved chunks might include the relevant section of your documentation on rate limits, the comparison table from your pricing page, and an FAQ entry about API access. All three are relevant, and together they give the model a comprehensive picture.
Step 5: Chunks are passed to the LLM as context
The language model receives a structured input: the user's question, combined with the retrieved content chunks. Its instructions specify that it should answer using the provided context as its primary reference, and should not speculate beyond what the context supports.
The model is no longer answering from general knowledge. It is reasoning about and synthesizing specific, curated content from your knowledge base.
Step 6: The model generates a grounded response
Using the retrieved content as its primary reference, the model generates a natural-language response. It explains the relevant information clearly, addresses the specific question asked, and maintains an appropriate tone. If the retrieved content does not contain a clear answer to the question, a properly configured model will say so rather than fabricating.
Step 7: Response is returned to the user
The generated response appears in the chat interface. From the user's perspective, it is a conversational answer to their question. Under the surface, it is a synthesis of the most relevant content from your knowledge base, expressed in natural language.
Why Vector Search Is Fundamentally Better Than Keyword Search
This distinction matters enough to address directly, because many businesses have prior experience with chatbots or help desk systems that use keyword matching. The difference is not marginal. It is architectural.
Keyword search finds exact or near-exact string matches. A system indexed on the phrase "return policy" will find content when a user types "return policy." It will miss content, or produce no results, when the user types "can I get my money back," "what if I want to send it back," "do you do exchanges," or "refund timeline." Each of those phrasings expresses the same intent but uses different words.
The solution in keyword-based systems is to manually define synonyms, aliases, and alternative phrasings. Someone has to anticipate every way a user might ask about returns and add those variations to the system. This does not scale. Real customer language is far more varied than any manual synonym list can capture.
Vector search operates on meaning. The embedding model encodes semantic content, not literal strings. "Can I get my money back" and "return policy" will produce similar embeddings because they refer to the same concept. The search finds relevant content regardless of the specific words used.
This matters enormously for real-world deployment because customers do not phrase questions the way documentation is written. They use casual language, incomplete sentences, colloquialisms, and sometimes incorrect terminology. A vector search-based system handles this naturally. A keyword system requires constant manual maintenance to keep up with the variation.
The practical outcome: RAG-based chatbots with vector search achieve 40-65% higher answer relevance rates compared to keyword-matching systems on the same knowledge base (McKinsey AI Report, 2025). The same content, accessed through a semantically aware retrieval system, produces dramatically better answers.
RAG vs. Alternatives: A Detailed Comparison
The market offers several approaches to knowledge-grounding AI chatbots. Understanding the trade-offs is important for making an informed platform choice.
Fine-tuning modifies the model itself by continuing to train it on domain-specific content. The model's internal weights are adjusted to encode specific knowledge. It is expensive, requires specialized expertise, takes days to weeks per iteration, and becomes stale as soon as your content changes. A fine-tuned model capturing your pricing in Q1 cannot reflect a Q2 pricing change without a full retraining run.
Full context stuffing places your entire knowledge base in the model's context window on every request. Modern models support large context windows (100K tokens or more), so this is technically feasible for small knowledge bases. It is expensive per request, slow, and produces degraded response quality as context length increases. Research has consistently shown that LLM attention quality degrades for information appearing in the middle of very long contexts (Liu et al., 2023). It does not scale beyond small, static knowledge bases.
Keyword matching predates the LLM era. It is fast and completely predictable but fundamentally unable to handle natural language variation. It works acceptably for very narrow, well-defined use cases where all question variations can be manually anticipated and indexed.
RAG combines the language capability of a current, powerful LLM with precise retrieval of domain-specific content. It handles natural language variation, updates instantly when the knowledge base updates, and grounds responses in explicit content rather than model inference.
| Dimension | RAG | Fine-Tuning | Keyword Matching | Full Context Stuffing |
|---|---|---|---|---|
| Accuracy on domain questions | High | High (for trained topics) | Low to moderate | Moderate (degrades with length) |
| Cost per query | Low to moderate | Low (after training) | Very low | High |
| Update ease | Very easy (add/update content) | Very difficult (full retrain) | Moderate (manual edits) | Easy but expensive at scale |
| Hallucination risk | Low | Moderate on untrained topics | None (returns stored text) | Low to moderate |
| Setup complexity | Moderate | Very high | Low | Low |
| Handles natural language variation | Yes | Yes | No | Yes |
| Best for | Business chatbots, support, sales | Highly specialized models with large proprietary datasets | Simple menu-driven bots | Very small knowledge bases |
| Knowledge freshness | Real-time on update | Stale until retrained | Real-time on edit | Real-time on update |
For business chatbot deployments, RAG is the dominant architecture for a reason. It occupies the right trade-off point: accurate, updatable, cost-effective, and capable of handling the natural language variation that characterizes real customer questions.
Real-World RAG Performance
RAG performance against domain-specific question sets is well-documented:
- RAG systems improve answer accuracy by 40-60% compared to ungrounded LLMs on domain-specific questions (Meta AI Research, 2025)
- Hallucination rates on domain-specific questions drop 75-85% when RAG is implemented versus prompt-only LLMs (Stanford HAI, 2025)
- First-pass accuracy rates of 85-92% are consistently achievable with well-structured, current knowledge bases (Gartner, 2025)
- 92% of enterprise AI chatbot deployments in 2025 used some form of RAG architecture, up from 71% in 2023 (Forrester, 2025)
- Businesses using RAG-based chatbots report 35-50% reductions in support ticket volume compared to deployments without knowledge grounding (Zendesk Benchmark Report, 2025)
These numbers reflect what well-implemented RAG looks like in production. The gap between RAG and non-grounded alternatives is not a marginal improvement. It is the difference between a chatbot that is genuinely useful and one that is a liability.
RAG Limitations: What It Cannot Fix
RAG is the right architecture for most business chatbot deployments, but it has genuine limitations that are worth understanding.
Quality depends entirely on source content. RAG retrieves and synthesizes what you give it. If your documentation is incomplete, ambiguous, or outdated, the chatbot's answers will reflect those problems. The system cannot invent accurate information about your business. It can only work with what is in the knowledge base. This makes content quality the primary operational variable, not the technical implementation.
Retrieval fails on absent content. If a user asks about something that is not covered in the knowledge base, the retrieval step will return low-relevance or irrelevant chunks. A well-configured model will respond with "I don't have information about that" rather than hallucinate, but the user still does not get an answer. Coverage gaps need to be addressed by expanding the knowledge base, not by hoping the model will fill them in.
Very long or complex documents may chunk poorly. A 200-page technical manual with heavily interdependent sections may not chunk cleanly. Information that is only meaningful in the context of surrounding content can become misleading when retrieved in isolation. Well-designed RAG implementations address this with overlapping chunks and metadata that preserves context, but it requires thoughtful content structuring.
Multi-hop reasoning can be challenging. Some questions require synthesizing information from multiple sources in a specific logical sequence. "What is the cheapest plan that includes API access and allows more than 5 team members?" requires retrieving and cross-referencing plan features, API availability, and team member limits from potentially separate documents. RAG handles this better than alternatives, but complex multi-step inference is still an area of active improvement.
Understanding these limitations is not a reason to avoid RAG. It is a reason to structure your knowledge base well, monitor performance systematically, and treat the knowledge base as an operational asset that requires ongoing maintenance.
How Paperchat Implements RAG
Paperchat is built on the RAG architecture. When you create a chatbot in Paperchat and add training content, the following pipeline runs automatically:
Your content (from URLs, uploaded files, or manually entered text) is extracted and chunked into segments. Each chunk is embedded using OpenAI's text-embedding model and stored in PGVector, a PostgreSQL extension for vector similarity search. When a user sends a message, Paperchat converts the message to an embedding, runs a semantic similarity search against your stored vectors, retrieves the top relevant chunks, and passes them to the language model as grounding context alongside the user's question.
The result is a response that draws from your specific content rather than general model knowledge. Pricing answers reflect your pricing. Policy answers reflect your policies. Feature questions are answered based on your documentation.
Because the knowledge base is stored in PGVector and separate from the model itself, updates are immediate. You can re-crawl a URL after updating a pricing page, upload a new policy document, or add a new Q&A pair, and the chatbot's answers reflect those changes on the next message. No retraining, no delay, no engineering work required.
Paperchat supports multiple content sources within the same knowledge base: website pages, uploaded PDFs and Word documents, and manually entered text and Q&A pairs. This means a business can combine structured documentation, support articles, and hand-crafted answers for specific high-priority questions in a single coherent knowledge base.
The Business Case for RAG-Based Chatbots
The technical case for RAG is clear. The business case is even clearer.
A chatbot that gives accurate, business-specific answers builds customer confidence, reduces the volume of questions that require human attention, and creates a self-service experience that is genuinely faster than waiting for an email response. A chatbot that hallucinate specific details about your business destroys confidence, creates support burden as agents have to correct misinformation, and gives customers a reason to distrust your digital touchpoints.
The accuracy difference between RAG-based and non-grounded chatbots on business-specific questions is not a technical detail. It is the difference between a tool that serves your customers well and one that does not.
Every hour your support team spends correcting chatbot misinformation is an hour that RAG eliminates. Every customer who builds incorrect expectations based on hallucinated answers is a downstream support conversation that RAG prevents. The return on investing in proper knowledge base setup and maintenance compounds over time, every time a customer gets an accurate answer without needing a human.
More Articles
How to Train an AI Chatbot on Your Own Business Data
Learn how to feed your website, documents, and FAQs into Paperchat so your AI chatbot answers like an expert on your business.
March 29, 2026
7 Mistakes to Avoid When Training Your AI Chatbot
The difference between a chatbot that builds trust and one that frustrates customers often comes down to training quality. Here are the seven most common mistakes, and how to fix them.
April 12, 2026
How to Sync Your Website Content with Your AI Chatbot Automatically
Keep your Paperchat knowledge base up to date with your website without manual updates — using scheduled crawls, webhooks, and CMS integrations.
March 29, 2026