
The decision to deploy an AI chatbot is straightforward. The harder question - the one most businesses do not ask rigorously enough until problems surface - is what separates a chatbot response that customers find genuinely useful from one that leaves them frustrated, confused, or reaching for the phone.
Not all chatbot responses are equal. The quality spectrum runs from actively damaging (confidently wrong answers that erode trust) to technically correct but unhelpful (accurate in the narrow sense but missing what the customer actually needed) to excellent (accurate, specific, actionable, appropriately toned, and delivered with the right amount of information). Most implementations land somewhere in the middle - correct enough to avoid disaster, but not optimized for the outcomes that make the investment worthwhile.
That gap between "correct enough" and "excellent" has measurable consequences. First-contact resolution rates, customer satisfaction scores, conversion rates from chat interactions, and escalation rates all vary significantly between well-tuned and poorly-tuned implementations. Understanding what excellent looks like - and how to train toward it - is what determines whether a chatbot deployment becomes a genuine business asset or a liability that quietly increases customer frustration.
The Quality Spectrum: From Harmful to Excellent
Before examining characteristics and training approaches, it helps to be precise about what failure looks like at different points on the spectrum.
The damaging end is where hallucination lives. The AI confidently states a return window of 60 days when the actual policy is 30. It quotes a price that was updated six months ago. It describes a feature that was deprecated. These responses are worse than no response at all, because they create expectations the business cannot fulfill and establish a trust deficit that affects every subsequent interaction.
The technically-correct-but-unhelpful middle is where most implementations sit. The chatbot answers the literal question but not the underlying question. A customer asks "do you ship to Canada?" and receives "Yes, we ship to Canada" - technically accurate but missing the cost, transit time, customs considerations, and applicable restrictions that the customer actually needed to make a decision. The interaction required a human follow-up anyway, defeating much of the automation value.
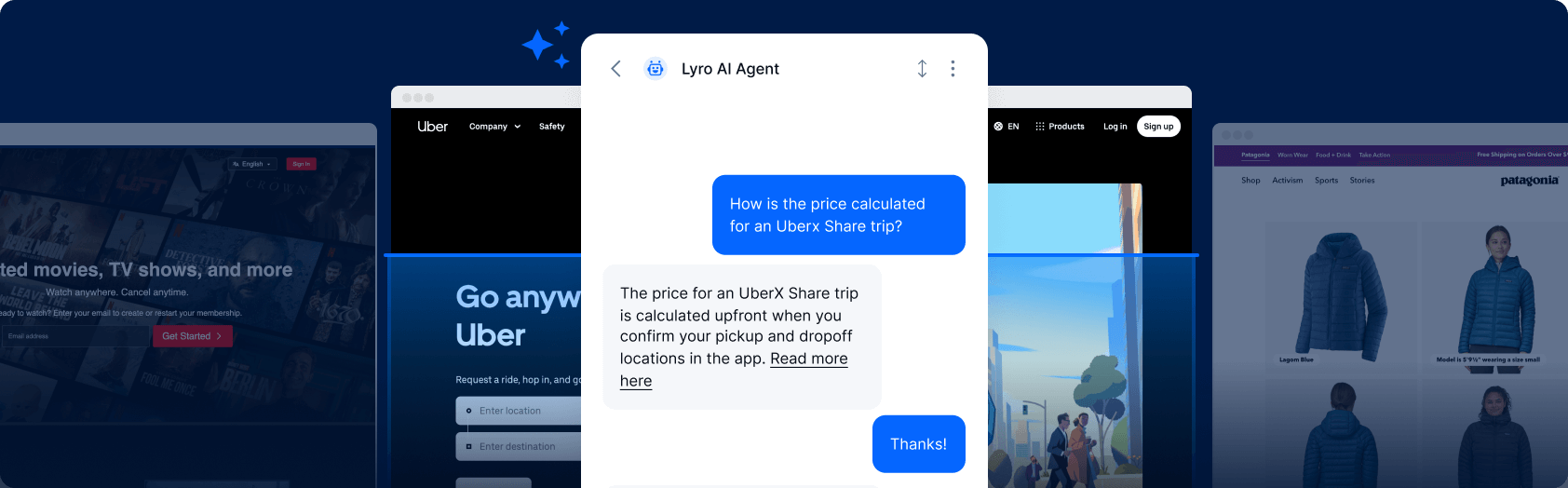
The excellent end is accurate, specific, efficient, and moves the customer forward. The same Canada shipping question gets a response that confirms availability, states the shipping cost range, gives the transit time estimate, notes that customs duties may apply, and links to the full international shipping policy. The customer has what they need. The interaction closes without escalation.
The distance between the middle and the excellent end is largely a function of training quality, knowledge base depth, and configuration - not a fundamental capability limitation.
The 7 Characteristics of an Excellent AI Chatbot Response
1. Accurate
This is the non-negotiable foundation. An accurate response is grounded in the business's actual policies, products, pricing, and procedures - not in generic language model knowledge or in outdated documentation. Accuracy requires that the knowledge base the chatbot is trained on is correct and current.
The technical mechanism matters here. AI chatbots using retrieval-augmented generation (RAG) - where the model retrieves relevant chunks from a curated knowledge base before generating a response - produce substantially more accurate answers than chatbots relying on base model knowledge alone. The retrieved content anchors the response to documented fact.
2. Specific
A response that could have been written for any business in any industry is a failure of specificity. When a customer asks about your return policy, they need your return policy - the actual window, the conditions, the process, and any exceptions. A response that describes "typical industry return policies" or uses placeholder-level generality is not serving the customer.
Specificity is a training quality issue. The knowledge base must contain specific, detailed content about the business's actual offerings, policies, and procedures. Thin, high-level documentation produces generic responses. Detailed, specific documentation produces specific responses.
3. Concise
Length is a proxy for clarity, and most chatbot implementations err on the side of too much. Research from Intercom's platform data shows that chatbot responses over 150 words see a 23% higher abandonment rate - customers stop reading and either escalate or leave. The mobile context makes conciseness even more important: a response that looks reasonable on a desktop screen becomes a wall of text in a chat widget on a phone.
The discipline here is answering the question in the fewest words that accurately address it. Not the most words that could plausibly relate to it. If the answer is two sentences, it should be two sentences. If clarification is needed, a follow-up question is better than a preemptive essay.
4. Actionable
Good responses tell the customer what to do next, not just what is true. "Our return policy is 30 days" is informative. "Our return policy is 30 days from delivery. To start a return, go to your account Orders page and click 'Start Return' - it takes about 2 minutes" is actionable. The customer knows what to do. The interaction is complete without requiring another question.
Actionability requires that the knowledge base includes procedural information, not just policy statements. The configuration work involves ensuring that responses to process-related questions include the next step, not just the policy.
5. Contextual
A new customer asking about pricing is in a different state of mind than an existing customer asking about cancellation. A prospect researching features needs different information than an active subscriber troubleshooting an issue. An excellent AI chatbot response adjusts based on available context: what page the customer is on, whether they are an existing account holder, what they asked earlier in the same conversation.
Context-awareness is partly a platform capability and partly a configuration choice. At minimum, the chatbot should respond differently based on what the conversation has already covered - not re-introducing information the customer has already provided, and not treating each message as if it exists in isolation.
6. Appropriately Toned
Customers arrive at a chatbot with different emotional states. A neutral inquiry about features needs a professional, efficient tone. A frustrated customer describing a problem that has already taken three days to resolve needs warmth, acknowledgment, and urgency. An angry customer escalating a complaint needs a response that does not feel defensive or dismissive.
Tone mismatch is a significant driver of CSAT decline in AI chat. A chatbot that responds to evident frustration with the same chipper, "Great question!" energy it uses for neutral inquiries makes the frustration worse. Well-configured implementations detect sentiment signals and adjust tone accordingly - leading with acknowledgment before moving to information.
7. Seamlessly Escalates
For the 20 to 40% of inquiries that genuinely require human involvement, the escalation should feel like a natural continuation, not a wall. An excellent handoff acknowledges what the AI has already gathered, sets clear expectations about next steps, confirms that the human follow-up will happen, and - where possible - transfers the conversation context so the customer does not repeat themselves.
The failure mode is abrupt termination: "I can't help with that. Please contact our support team at support@example.com." No acknowledgment of what was already discussed, no context carried forward, no timing expectation. The customer experience is worse than if they had emailed in directly.
The Comparison: Poor vs. Excellent Response Characteristics
| Dimension | Poor Response | Excellent Response |
|---|---|---|
| Accuracy | Hallucinates pricing or policy details not in knowledge base | Grounded in specific, current business documentation |
| Specificity | Generic answer applicable to any business | Specific to this business's actual policies and products |
| Length | 200+ words covering tangentially related topics | 50-100 words addressing exactly what was asked |
| Next steps | Describes what is true, leaves customer to figure out what to do | States what to do next and how to do it |
| Context use | Treats each message as an isolated query | References earlier conversation context; adjusts for customer type |
| Tone | Same cheerful tone regardless of customer frustration | Matches the customer's emotional state; leads with acknowledgment for frustrated customers |
| Escalation | Abrupt "can't help, email us" with no context transfer | Warm transition with context, timing expectation, and proactive follow-up |
| Hallucination rate | 15-30% on topics not well-covered in knowledge base | Under 5% with comprehensive, well-structured training content |
| Average CSAT | 3.2/5 | 4.5/5 |
Response Quality: Poorly Trained vs. Well-Trained Chatbot
Comparative score (0-100) across the 7 key dimensions of chatbot response quality
Illustrative benchmarks based on industry research: Intercom, Zendesk CX Trends 2025, Freshworks AI Report 2025
How Training Quality Determines Response Quality
The Knowledge Base is the Foundation
Everything downstream from training depends on the quality of the source content. A chatbot trained on accurate, complete, clearly written documentation about the business produces accurate, complete, clearly written responses. A chatbot trained on a sparse two-page FAQ produces responses that are inadequate for any question that falls slightly outside those two pages.
The failure mode most businesses encounter is not AI capability - it is documentation coverage. When the chatbot says "I don't have information about that," and the answer is actually somewhere in the company's knowledge base, the problem is almost always retrieval - the relevant document was not included, was in a format the indexing process did not capture, or was structured in a way that makes it hard to retrieve.
Chunking and Retrieval Quality
How documentation is divided and indexed affects what gets retrieved when a question is asked. Overly long chunks mean the retrieved content includes a lot of irrelevant material, which dilutes the response. Overly short chunks miss the context needed to give a complete answer. Well-structured content - with clear headings, discrete topics per section, and logical organization - produces better retrieval results.
This is a technical consideration that most businesses do not need to manage directly if the platform handles it. What businesses do need to manage is the structure of their source content: long walls of undifferentiated text produce worse retrieval results than well-organized documents with clear sections.
Coverage Gaps and Confident Wrongness
The most dangerous failure mode in AI chat is what might be called "confident wrongness" - the model generates a plausible, fluently stated response on a topic where the knowledge base is thin, drawing partly on general training data rather than business-specific content. The response sounds correct. It may be partially correct. But it contains specifics - a price, a policy detail, a product capability - that are wrong.
Coverage gaps are addressed by auditing actual customer questions against the knowledge base and identifying topics that generate poor responses. The fix is almost always documentation: add the missing content, update outdated information, and restructure content that is technically present but poorly organized for retrieval.
How to Test Your Chatbot's Response Quality
The 20-Question Test
Before deployment and after every significant knowledge base update, write 20 questions that represent the most common and most consequential inquiries the chatbot will receive. These should be drawn from real support history: what are the actual questions customers ask most frequently? Test all 20 against the current implementation and score each response against the 7 quality dimensions above.
A well-trained chatbot should produce accurate, specific, actionable responses for at least 17 of the 20. Where it falls short, the failure mode identifies the fix: coverage gap, retrieval issue, length configuration, or tone setting.
Adversarial Testing
Ask questions that are adjacent to but outside the knowledge base. The goal is not to break the chatbot - it is to understand how it handles uncertainty. An excellent implementation says "I don't have specific information about that - would you like me to connect you with our support team?" A poor implementation confidently fabricates an answer.
Adversarial testing should include: questions about competitors, hypothetical scenarios outside business policy, requests for information the business does not publish, and questions about topics that have changed recently. The responses to these edge cases define the ceiling of customer trust.
Tone Testing
Submit the same substantive question in three emotional registers: neutral, frustrated, and polite/enthusiastic. An excellent implementation adjusts tone across all three. A poor implementation responds identically regardless of the customer's evident state.
Specific frustrated-tone tests should include phrases like "this is really frustrating," "I've been trying to get an answer for days," and "this is unacceptable." If the chatbot responds to these with the same tone as neutral queries, the tone configuration needs work.
Escalation Testing
Ask questions that should trigger human handover - complex billing disputes, situations requiring account-level access, expressions of intent to cancel, or explicit requests for a human agent. Verify that the escalation triggers correctly, that the transition message is warm and contextual, and that the customer's information is captured for follow-up.
Training Practices That Improve Response Quality Over Time
Monthly Conversation Review
Pull a representative sample of chatbot conversations each month - at minimum 50 to 100 interactions - and evaluate them against the quality framework. Flag responses that are too long, too generic, inaccurate, or missing actionable next steps. The patterns that emerge from this review drive the knowledge base updates and configuration changes for the following month.
This practice also surfaces the questions the chatbot is failing on that were not anticipated during initial setup. Real customer language diverges from how businesses describe their own products and processes. Customers ask "do you take PayPal?" when the documentation says "accepted payment methods." The gap is bridgeable, but only if someone is reading the conversations.
Gap Identification and Documentation Updates
Every time the chatbot answers poorly, the root cause is usually identifiable: the topic is not covered, the coverage is thin, the documentation is outdated, or the content is structured in a way that makes retrieval difficult. Each failure is a documentation task.
Building a practice of treating poor chatbot responses as documentation signals - not AI capability limitations - keeps the quality curve moving in the right direction. Well-maintained implementations improve substantially in the first six months because the volume of real conversations exposes documentation gaps faster than any upfront audit can.
Configuration Tuning for Response Length
Most AI chatbot platforms allow configuration of response length preferences by question type or topic. Short factual questions should get short answers. Complex troubleshooting questions can accommodate more detail. Setting these parameters based on actual conversation data - where do customers abandon reading? where do they ask follow-up questions because the initial answer was incomplete? - produces a configuration that matches the business's actual interaction patterns.
Benchmarks for Well-Trained Implementations
The performance gap between average and well-trained implementations is substantial:
| Metric | Average Implementation | Well-Trained Implementation |
|---|---|---|
| Accuracy rate | 65-72% | 85-92% |
| Customer satisfaction (AI chat) | 3.2-3.8 / 5 | 4.3-4.7 / 5 |
| First-contact resolution rate | 45-55% | 75-83% |
| Escalation rate | 35-50% | 15-25% |
| Response length (avg words) | 180-220 | 80-120 |
| Repeat contact rate (same issue) | 28-35% | 12-18% |
The accuracy and first-contact resolution differences here are the most consequential. A chatbot that resolves 75-83% of contacts without escalation at 89% accuracy is producing fundamentally different customer outcomes than one resolving 45% at 68% accuracy. The gap is trainable - but it requires the systematic approach described above, not a one-time setup.
Platform choice matters as well. Paperchat's RAG-based architecture means responses are grounded in business-specific training content from the moment of deployment. The knowledge base is the primary source, which reduces hallucination risk and makes accuracy a function of content quality rather than a black-box model behavior. Businesses can see what content is being retrieved for a given question, which makes debugging poor responses straightforward rather than opaque.
The goal of great AI chatbot responses is not to pass a Turing test. It is to give customers accurate information, move them forward, and build the kind of reliable interaction experience that makes them return to the chatbot the next time they have a question - instead of reaching for the phone or opening a ticket.
More Articles
7 Mistakes to Avoid When Training Your AI Chatbot
The difference between a chatbot that builds trust and one that frustrates customers often comes down to training quality. Here are the seven most common mistakes, and how to fix them.
April 12, 2026
How to Train an AI Chatbot on Your Own Business Data
Learn how to feed your website, documents, and FAQs into Paperchat so your AI chatbot answers like an expert on your business.
March 29, 2026
8 Ways AI Chatbots Reduce Support Ticket Volume
A detailed breakdown of how AI chatbots cut inbound support ticket volume, with current performance benchmarks, real case studies, and practical guidance on implementation.
April 8, 2026